This assignment uses a Multi-nomial Logit (MNL) model to analyze (1) yogurt purchase data made by consumers at a retail location, and (2) conjoint data about consumer preferences for minivans.
1. Estimating Yogurt Preferences using a Multi-nomial logit model
Background on the Likelihood for the Multi-nomial logit Model
A multi-nomimal logit (MNL) model is an extension of the traditional binary logit model and used when the dependent variable has more than two categories or levels. In a MNL model, the probabilities of each category are modeled simultaneously using a set of independent variables and the probabilities sum up to 1 across all categories.
Our MNL model will estimate parameters for each explanatory variable which represent the effect of that variable on the odds of choosing one alternative over the others. These parameters are typically estimated using maximum likelihood estimation.
Suppose we have \(i=1,\ldots,n\) consumers who each select exactly one product \(j\) from a set of \(J\) products. The outcome variable is the identity of the product chosen \(y_i \in \{1, \ldots, J\}\) or equivalently a vector of \(J-1\) zeros and \(1\) one, where the \(1\) indicates the selected product. For example, if the third product was chosen out of 4 products, then either \(y=3\) or \(y=(0,0,1,0)\) depending on how we want to represent it.
Suppose we also have a vector of data on each product that is represented by \(x_j\) (eg, size, price, etc.).
We can then model the consumer’s decision as the selection of the product that provides the most utility, and we’ll specify the utility function as a linear function of the product characteristics:
\[ U_{ij} = x_j'\beta + \epsilon_{ij} \]
where \(x_j\) is the vector of product data and \(\epsilon_{ij}\) is a random error term.
Because we have chosen the specific type of randomness (The choice of the i.i.d. extreme value error term), it becomes possible to derive a simple formula to predict the likelihood of a consumer choosing a particular product from the set of products listed:
For example, if there are 4 products, the probability or likelihood that consumer \(i\) chooses product 3 is: \[ \mathbb{P}_i(3) = \frac{e^{x_3'\beta}}{e^{x_1'\beta} + e^{x_2'\beta} + e^{x_3'\beta} + e^{x_4'\beta}} \]
Therefore, to figure out how likely it is that a consumer made their specific choice of product, you can multiply the probabilities of choosing each product together, but only the probability of the actual chosen product affects the final result because of the indicator variable. r \(i\) is the product of the \(J\) probabilities, each raised to the power of an indicator variable(\(\delta_{ij}\)) that indicates the chosen product:
Just to note, the \(\delta_{ij}\) indicator variable acts as a switch that is “on” (equal to 1) when the specific condition (consumer ii choosing product jj) is met, and “off” (equal to 0) when it is not. In the context of the likelihood function described, the indicator variable helps in the following way:
When \(\delta_{ij}\) = 1, the probability of choosing product jj is included in the calculation.
When \(\delta_{ij}\) = 0, the probability of choosing product jj is effectively ignored (since raising any number to the power of 0 gives 1, which does not affect the product).
Notice that if an individual consumer selected product \(j=3\), then \(\delta_{i3}=1\) while \(\delta_{i1}=\delta_{i2}=\delta_{i4}=0\), then the individual likelihood is:
To find the overall probability of all consumers making their choices, we will find the joint likelihood by simply multiplying the individual probabilities for each consumer together:
Finally, we can take the logarithm of the joint likelihood. This changes the multiplication of probabilities into a sum of logarithms, which makes it much easier math to hande.
We will use the yogurt_data dataset, which provides anonymized consumer identifiers (id), a vector indicating the chosen product (y1:y4), a vector indicating if any products were “featured” in the store as a form of advertising (f1:f4), and the products’ prices (p1:p4). For example, consumer 1 purchased yogurt 4 at a price of 0.079/oz and none of the yogurts were featured/advertised at the time of consumer 1’s purchase. Consumers 2 through 7 each bought yogurt 2, which for consumer 2, 3, 4, and 5 was priced at 0.098/oz. Customer 6 also purchased yogurt 2, but when it was priced at 0.092/oz and consumber 7 purchased it at 0.081/oz.
import pandas as pd import numpy as np yogurt = pd.read_csv('data/yogurt_data.csv')yogurt.head(15)
id
y1
y2
y3
y4
f1
f2
f3
f4
p1
p2
p3
p4
0
1
0
0
0
1
0
0
0
0
0.108
0.081
0.061
0.079
1
2
0
1
0
0
0
0
0
0
0.108
0.098
0.064
0.075
2
3
0
1
0
0
0
0
0
0
0.108
0.098
0.061
0.086
3
4
0
1
0
0
0
0
0
0
0.108
0.098
0.061
0.086
4
5
0
1
0
0
0
0
0
0
0.125
0.098
0.049
0.079
5
6
0
1
0
0
0
0
0
0
0.108
0.092
0.050
0.079
6
7
0
1
0
0
0
0
0
0
0.103
0.081
0.049
0.079
7
8
0
0
0
1
0
0
0
0
0.108
0.086
0.054
0.079
8
9
1
0
0
0
0
0
0
0
0.108
0.098
0.050
0.079
9
10
1
0
0
0
0
0
0
0
0.108
0.098
0.050
0.079
10
11
1
0
0
0
0
0
0
0
0.108
0.098
0.050
0.079
11
12
1
0
0
0
0
0
0
0
0.108
0.098
0.050
0.079
12
13
0
0
0
1
0
0
0
0
0.108
0.081
0.050
0.086
13
14
0
0
0
1
0
0
0
0
0.108
0.081
0.050
0.086
14
15
0
0
0
1
0
0
0
0
0.108
0.081
0.050
0.079
This data gives us an overview of which customer bought what yogurt brand at a specific price and indicates if the product was featured at the time. Let the vector of product features include brand dummy variables for yogurts 1-3 (we’ll omit a dummy for product 4 to avoid multi-collinearity), a dummy variable to indicate if a yogurt was featured, and a continuous variable for the yogurts’ prices:
To start to calculate our maximum liklihood for our MNL model, we first want to reorganize the data from our wide to long shape with \(n \times J\) rows and a single column for each covariate. As part of this re-organization, we’ll add binary variables to indicate the first 3 products; the variables for featured and price are included in the dataset and simply need to be “pivoted” or “melted” from wide to long. By reorganizing the data this way, we can effectively analyze the likelihood of different choices using the MNL model.
yogurt["X_yogurt1"] = yogurt["y1"].apply(lambda x: 1if x ==1else0)yogurt["X_yogurt2"] = yogurt["y2"].apply(lambda x: 1if x ==1else0)yogurt["X_yogurt3"] = yogurt["y3"].apply(lambda x: 1if x ==1else0)yogurt = yogurt.copy()melted_featured = pd.melt(yogurt, id_vars = ["id"], value_vars = ["f1", "f2", "f3", "f4"], var_name ='featured', value_name ='X_featured')yogurt_melt = pd.merge(yogurt, melted_featured, on='id')melted_price = pd.melt(yogurt, id_vars = ["id"], value_vars= ['p1', 'p2', 'p3', "p4"], var_name ='value_p', value_name ='X_price')yogurt_melt = pd.merge(yogurt_melt, melted_price, on ="id")## now melting yogurt brands to create a column called yogurt_chosenyogurt_melt_again = pd.melt(yogurt, id_vars = ['id'], value_vars = ['y1', 'y2', 'y3'], var_name ='y_feature', value_name ='yogurt_chosen')#want to merge the data frames together on the id fieldyogurt_melt1 = pd.merge(yogurt_melt, yogurt_melt_again, on ="id")#only choosing the fields needed from our merged dataframeyogurt_melt1 = yogurt_melt1[["id","X_yogurt1", "X_yogurt2", "X_yogurt3", "X_featured", "X_price", "yogurt_chosen"]]yogurt_melt1.head()
id
X_yogurt1
X_yogurt2
X_yogurt3
X_featured
X_price
yogurt_chosen
0
1
0
0
0
0
0.108
0
1
1
0
0
0
0
0.108
0
2
1
0
0
0
0
0.108
0
3
1
0
0
0
0
0.081
0
4
1
0
0
0
0
0.081
0
Now we have a dataframe that will enable us to effectively analyze the likelihood of different choices via our MNL model. To being this process, we need to define our log-likelihood function. Our log_likelihood function has 3 inputs: - params - the array containing the parameter values to be optimized - data - our data from the yogurt survey
Our function will return the log-likelihood of the MNL Model.
from scipy.optimize import minimizefrom scipy import optimize# Define log-likelihood functiondef neg_log_likelihood(params, data): beta1, beta2, beta3, beta_f, beta_p = params# Extract dataid= data['id'] value = data['yogurt_chosen'] yogurt_1 = data['X_yogurt1'] yogurt_2 = data['X_yogurt2'] yogurt_3 = data['X_yogurt3'] X_price = data['X_price'] X_featured = data['X_featured']# Calculate probability of buying np_exponent = np.exp(beta1 * yogurt_1 + beta2 * yogurt_2 + beta3 * yogurt_3 + beta_f * X_featured + beta_p * X_price) p_buy = np_exponent / (1+ np_exponent)# Calculate log-likelihood for each observation log_likelihoods = value * np.log(p_buy) + (1- value) * np.log(1- p_buy)# Sum up log-likelihoods to get the joint log likelihood joint_log_likelihood_value = np.sum(log_likelihoods)return-joint_log_likelihood_value # Return negative log-likelihood for minimization# Define initial guess for parametersinitial_params = [ 1, 1, 1, 1, -1]# Call minimize to find MLEsresult = optimize.minimize(neg_log_likelihood, initial_params, args=(yogurt_melt1,))# want to extract the mle parameters and our interceptmle_params = result.x# Print MLEsprint("Maximum Likelihood Estimates (MLEs) for parameters:")print("Beta1:", mle_params[0])print("Beta2:", mle_params[1])print("Beta3:", mle_params[2])print("Beta_f:", mle_params[3])print("Beta_p:", mle_params[4])print(mle_params)
The intercepts for the yogurt products are the coefficients or Betas for yogurt1, yogurt2, and yogurt3. These coefficients represent the preferences for each yogurt product when all other variables are held constant. - Our Beta1 value is 1.2468. This coefficient represents the effect of the first yogurt feature (X_yogurt1) on the likelihood of the yogurt being chosen. A positive value suggests that as X_yogurt1 increases by one unit, the log-odds of the yogurt being chosen increases by 1.2468 - Beta2 has a value of 1.2956: This coefficient represents the effect of the second yogurt feature (X_yogurt2). Similarly, a positive value indicates that an increase in X_yogurt2 by one unit increases the log-odds of the yogurt being chosen by 1.2956. - Beta3 has a value of 1.2183: This coefficient represents the effect of the third yogurt feature (X_yogurt3). Again, a positive value means that an increase in X_yogurt3 by one unit increases the log-odds of the yogurt being chosen by 1.2183. - The Beta_f has a value of -0.267: This coefficient represents the effect of the yogurt being featured (X_featured). The negative value suggests that if the yogurt is featured, the log-odds of it being chosen decrease by 0.267. This might seem counterintuitive, as one might expect featured products to be more likely to be chosen. It could indicate that the featured status alone doesn’t make a yogurt more appealing or there might be other factors at play such as price or brand loyalty. - Beta_p has a value of -25.036: This coefficient represents the effect of the price (X_price) on the likelihood of the yogurt being chosen. A very large negative value indicates that an increase in price significantly decreases the log-odds of the yogurt being chosen. This makes intuitive sense, as higher prices generally deter purchases.
In summary, the output of our log likelihood function indicates that Positive betas (Beta1, Beta2, Beta3) correspond with an increase in the respective yogurt features make it more likely that the yogurt will be chosen. The negative beta for being featured (Beta_f) suggests a decrease in likelihood when the yogurt is featured. The highly negative beta for price (Beta_p) indicates that higher prices significantly reduce the likelihood of the yogurt being chosen. The negative coefficient indicates that as the price increases, the likelihood of purchase decreases. This is consistent with economic theory and consumer behavior.
beta_p =-25.036# Estimated price coefficientintercepts = [1.2468, 1.2956, 1.21839] # Intercepts for yogurt products# Identify the most preferred and least preferred yogurtmost_preferred_index = np.argmax(intercepts)least_preferred_index = np.argmin(intercepts)# Calculate the utility differenceutility_difference = intercepts[most_preferred_index] - intercepts[least_preferred_index]# Calculate the dollar benefit using the price coefficientdollar_benefit = utility_difference * beta_pprint("Dollar benefit between the most-preferred and least-preferred yogurt: $", dollar_benefit)
Dollar benefit between the most-preferred and least-preferred yogurt: $ -1.93302956
One benefit of the MNL model is that we can simulate counterfactuals (eg, what if the price of yogurt 1 was $0.10/oz instead of $0.08/oz).
import numpy as npfitted_params = [1.2468, 1.2956, 1.21839,-0.2677, -25.0363]# Original price of yogurt 1original_price_yogurt1 =0.108# Increase in price of yogurt 1price_increase =0.10# New price of yogurt 1new_price_yogurt1 = original_price_yogurt1 + price_increase# Calculate the utility for each product with the new price of yogurt 1utility_yogurt1_new_price = fitted_params[0] + fitted_params[1] + new_price_yogurt1 * fitted_params[4]utility_yogurt1_old_price = fitted_params[0] + fitted_params[1] + original_price_yogurt1 * fitted_params[4]utility_yogurt2 = fitted_params[0] + fitted_params[2] + original_price_yogurt1 * fitted_params[4]utility_yogurt3 = fitted_params[0] + fitted_params[3] + original_price_yogurt1 * fitted_params[4]utility_yogurt4 = fitted_params[0] + fitted_params[4] + original_price_yogurt1 * fitted_params[4]# Calculate choice probabilitiesprob_yogurt1_old_price = np.exp(utility_yogurt1_old_price) / (1+ np.exp(utility_yogurt1_old_price))prob_yogurt1_new_price = np.exp(utility_yogurt1_new_price) / (1+ np.exp(utility_yogurt1_new_price))prob_yogurt2 = np.exp(utility_yogurt2) / (1+ np.exp(utility_yogurt2))prob_yogurt3 = np.exp(utility_yogurt3) / (1+ np.exp(utility_yogurt3))prob_yogurt4 = np.exp(utility_yogurt4) / (1+ np.exp(utility_yogurt4))# Calculate market sharesmarket_share_yog1_old_price = prob_yogurt1_old_pricemarket_share_yogurt1_new_price = prob_yogurt1_new_pricemarket_share_yogurt2 = prob_yogurt2market_share_yogurt3 = prob_yogurt3market_share_yogurt4 =100-65.5# Print market sharesprint("Market share for yogurt 1 with new price: ", round(market_share_yogurt1_new_price*100,2))print("Market share for yogurt 1 with old price: ", round(market_share_yog1_old_price*100,2))print("Market share for yogurt 2: ", round(market_share_yogurt2*100,2))print("Market share for yogurt 3: ", round(market_share_yogurt3*100,2))print("Market share for yogurt 4: ", round(market_share_yogurt4,2))
Market share for yogurt 1 with new price: 6.51
Market share for yogurt 1 with old price: 45.97
Market share for yogurt 2: 44.06
Market share for yogurt 3: 15.13
Market share for yogurt 4: 34.5
Based on the change in price of yogurt 1 to $0.10/oz instead of $0.08/oz, we are able to predict how this influence market share. Therefore, with the increase in price, the market share for yogurt 1 dropped significantly from 45.97% to 6.51%. This further backs up the point that consumers are very sensitive to price changes, as highlighted by the beta from our MNL model.
2. Estimating Minivan Preferences via Conjoint Analysis
Conjoint Analysisis is an advanced quantitative markeitng research method popular for product and pricing research. Conjoint analysis has gained popularity in recent years because the survey questions mimic the tradeoffs people make in the real world. It enables researchers to quantify how a product attribute changes demand and evaluate the market acceptance of products before they launch.
In this case, we will be evaluating minivan preferences via conjoint analysis.
Data
import numpy as np import pandas as pd import statsmodels.api as smimport pyrsm as rsmconjoint = pd.read_csv('data/conjoint.csv')conjoint.head(6)
resp.id
ques
alt
carpool
seat
cargo
eng
price
choice
0
1
1
1
yes
6
2ft
gas
35
0
1
1
1
2
yes
8
3ft
hyb
30
0
2
1
1
3
yes
6
3ft
gas
30
1
3
1
2
1
yes
6
2ft
gas
30
0
4
1
2
2
yes
7
3ft
gas
35
1
5
1
2
3
yes
6
2ft
elec
35
0
This data contains the survey results from 200 respondents who compeleted 15 choice tasks with 3 alternatives given for each choice task. For each choice task there were 4 attributes seat number, cargo space, engine type, and price. Within the attributes, there are various levels. For number of seats, the levels are 6,7,8. Cargo Space has levels of 2ft and 3ft, Engine Type has levels of gas, hybrid, electric, and price in thousands of dollars). For each alternative given within the choice task, there is a binary column indicating which alternative-level combination was chosen.
For example, in the rows printed above we see that for the first choice task, respondent with the resp.id of 1 was given 3 choice options.
Option 1: 6 Seats, 2ft Cargo, Gas Engine, 35K
Option 2: 8 Seats, 3ft Cargo, Hybrid Engine, 30K
Option 3: 6 Seats, 3ft Cargo, Gas Engine, 30K
In this first choice task, respondent 1 chose option 3 as indicated by the binary column choice.
Model
#converting categorical variables into numerical variables to run the modelconjoint_dummies1 = pd.get_dummies(conjoint['cargo'], prefix ='cargo')conjoint_dummies2 = pd.get_dummies(conjoint["eng"], prefix ='eng')#concatenate the dummy variables back with the original dataframeconcat_conjoint = pd.concat([conjoint, conjoint_dummies1, conjoint_dummies2], axis =1)
#converting the yes, no's for carpool into 1s and 0sconcat_conjoint["carpool"] = rsm.ifelse(concat_conjoint["carpool"] =='yes',1,0)concat_conjoint.head()
resp.id
ques
alt
carpool
seat
cargo
eng
price
choice
cargo_2ft
cargo_3ft
eng_elec
eng_gas
eng_hyb
0
1
1
1
1
6
2ft
gas
35
0
True
False
False
True
False
1
1
1
2
1
8
3ft
hyb
30
0
False
True
False
False
True
2
1
1
3
1
6
3ft
gas
30
1
False
True
False
True
False
3
1
2
1
1
6
2ft
gas
30
0
True
False
False
True
False
4
1
2
2
1
7
3ft
gas
35
1
False
True
False
True
False
#converting the dummy true false variables into 1s and 0sconcat_conjoint[["cargo_2ft", "cargo_3ft", "eng_elec", "eng_gas", "eng_hyb"]] = concat_conjoint[["cargo_2ft", "cargo_3ft", "eng_elec", "eng_gas", "eng_hyb"]].astype(int)
#omit variables to avoid multi-collinearityconjoint_omit = concat_conjoint[(concat_conjoint['seat'] !=6)]#design matrixX = conjoint_omit[['seat', 'cargo_3ft', 'eng_elec','eng_hyb', 'price']]X = sm.add_constant(X) # Add intercept# Fit MNL modelmodel = sm.MNLogit(conjoint_omit['choice'], X)result = model.fit()# Display coefficients and standard errorsprint(result.summary())
Above is the output from our multi-nomial logit model generated using our conjoint survey data. We can use the coefficients from the output to determine which preferences are favored by survey respondents and quantify the utility value they offer the respondents. In this model, our constant refers to the variables we excluded to avoid multicollinearity and thus, they act as our baseline. Our baseline in this analysis is a car that seats 6 people, a gas engine and has a 2ft cargo space. When analyzing the coefficient values, we will compare how changing the levels of the attributes changes utility value in comparison to this baseline value.
In summary, the results show us that:
A one-unit increase in seat is associated with an increase in the log-odds of choosing choice=1 by approximately 0.2307, holding all other variables constant.
Having cargo_3ft is associated with an increase in the log-odds of choosing choice=1 by approximately 0.3890 compared to having cargo_2ft, holding all other variables constant.
eng_elec and eng_hyb are the indicators for electric and hybrid engines, respectively, compared to gas engines. Having an electric engine is associated with a decrease in the log-odds of choosing choice=1 by approximately 1.4520, while having a hybrid engine is associated with a decrease by approximately 0.7315, compared to gas engines.
Finally, an increase in price is associated with a decrease in the log-odds of choosing choice=1 by approximately 0.1556, holding all other variables constant. This means that people seem to be sensitive to changes in price and prefer to purchase vehicles that are less expensive.
Based on the coefficients from our model, respondents seem to prefer seat = 8, engine = gas, price = 30K, and cargo = 3ft.
Our price coefficient is -0.1556. This means that a one unit increase in the price variable is associateed with a decrease in the log-odds of choosing that combination by 0.1556, holding all other variables constants.
#price coefficient from modelprice_coeff =-0.1556# converting the price coefficientdollar_per_util =1/ price_coeff# dollar value of 3ft of cargo space compared to 2ftcargo_3ft_value =0.3890# coefficient for cargo_3ftcargo_2ft_value =0# reference categorycargo_space_value_difference = (cargo_3ft_value - cargo_2ft_value) * dollar_per_utilprint(f"The dollar value of 3ft of cargo space compared to 2ft of cargo space is approximately: ${cargo_space_value_difference:.2f}")
The dollar value of 3ft of cargo space compared to 2ft of cargo space is approximately: $-2.50
To predict the market shares of each minivan using the estimated parameters from the multinomial logistic regression, we can calculate the utility for each minivan and then use the softmax function to convert these utilities into probabilities. These probabilities will represent the market shares.
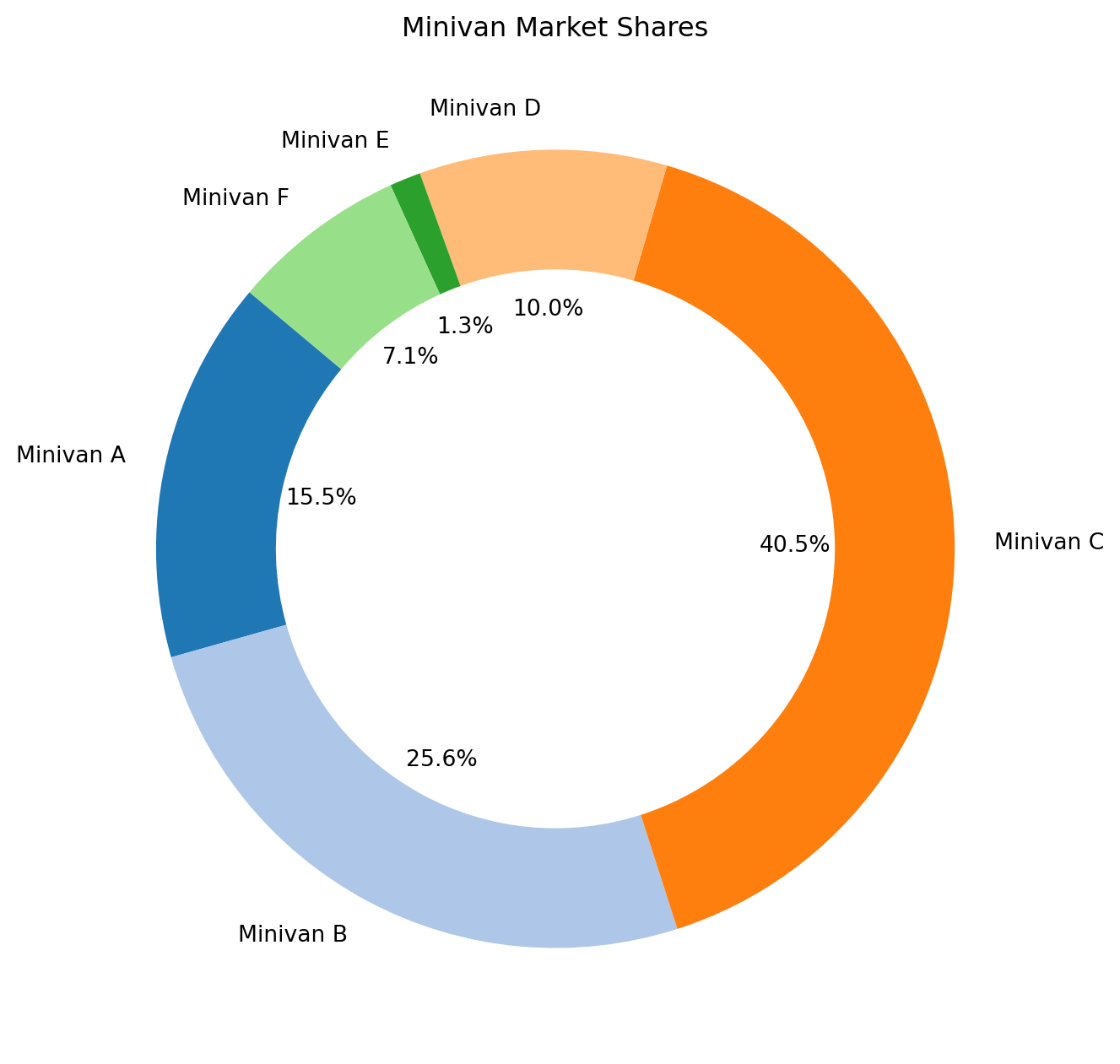
# Utility functiondef utility(seats, cargo, eng_elec, eng_hyb, price):return (beta_0 + beta_seat * seats + beta_cargo * cargo + beta_eng_elec * eng_elec + beta_eng_hyb * eng_hyb + beta_price * price)#utilities for each minivanutilities = np.array([utility(*van) for van in minivans])# Softmax function to get probabilities (market shares)def softmax(x): e_x = np.exp(x - np.max(x)) #want to subtract to prevent overflowreturn e_x / e_x.sum()# Calculate market sharesmarket_shares = softmax(utilities)# Print the resultsminivan_labels = ['Minivan A', 'Minivan B', 'Minivan C', 'Minivan D', 'Minivan E', 'Minivan F']for label, share inzip(minivan_labels, market_shares):print(f"{label}: {share:.4f} or {share *100:.2f}%")
Minivan A: 0.1549 or 15.49%
Minivan B: 0.2556 or 25.56%
Minivan C: 0.4055 or 40.55%
Minivan D: 0.1002 or 10.02%
Minivan E: 0.0126 or 1.26%
Minivan F: 0.0712 or 7.12%
Based on this code, we find that the market share is
Minivan A: 15.49%
Minivan B: 25.57%
Minivan C: 40.55%
Minivan D: 10.02%
Minivan E: 1.26%
Minivan F: 7.11%
These percentages represent the predicted market shares for each minivan based on the given model and parameters.
import matplotlib.pyplot as plt colors = plt.cm.tab20(range(6))# Create the pie chartfig, ax = plt.subplots(figsize=(8, 8))wedges, texts, autotexts = ax.pie(market_shares, labels=minivan_labels, autopct='%1.1f%%', startangle=140, colors=colors, wedgeprops=dict(width=0.3))# Add a titleplt.title('Minivan Market Shares')# Annotate each wedge with the corresponding market sharefor i, (wedge, share) inenumerate(zip(wedges, market_shares)): angle = (wedge.theta2 - wedge.theta1) /2.+ wedge.theta1 x = np.cos(np.radians(angle)) *1.2 y = np.sin(np.radians(angle)) *1.2# Display the pie chartplt.show()