This post explains and implements a few measures of variable importance for features of a payment card and their impact on customer satisfaction with that payment card.
1. Background on Variable Importance and Key Drivers Analysis
Variable importance and key drivers analysis are often used in conjunction when determining which variables contribute the most to a model’s predictive power. Different supervised machine learning models use various methods to calculate variable importance, with the same goal of trying to see which explanatory variable has the greatest impact on the response variable. We will review these different methods to identify variable importance below and implement them using a dataset examining customer satisfaction with a payment card.
Key Driver Analysis Methods from Linear Regression Models
Pearsons Correlation
In linear regression models, key drivers can be identified via the change in the value of the Pearson Correlation Coefficient. Pearson’s correlation coefficient is a measure used to quantify the linear relationship between two variables, and ranges from -1 to +1. A coefficient of +1 indicates a perfect positive linear relationship whereas -1 indicates a perfect negative linear relationship. 0 indicates no linear correlation.
Suppose we have 3 explanatory variables as part of our linear regression model. We can remove one variable at a time and recalculate our Pearson’s Correlation value. Features with high absolute values of the correlation coefficient (close to 1 or -1) are likely more important to our model’s predictive power because they have a strong linear relationship with the target variable. The sign can also indicate the direction of the relationship. A positive sign means that as the feature increases, the target increases and vice versa for the negative sign. We can use the correlation coefficient to rank the features based on the absolute value of their respective coefficients, thus features with higher absolute values are generally more influential in predicting the target variable in a linear regression context.
When calculating Pearon’s we take the covariance of 2 variables, and divide it by the product of their standard deviations. This formula inherently standardizes the covariance, meaning that Pearson’s correlation coefficient itself is already a standardized measure. Therefore, when implementing pearson’s, you do not need to standardize your data before finding the coefficient values.
However, it is critical to note that while strong correlations with the target variable are important, it’s also crucial to check the correlations between features. High correlation between features, i.e. multicollinearity, can affect the model’s stability and the interpretation of the coefficients.
Usefullness
Usefulnes is another measure derived from linear regression models. “Usefulness” or \({\Delta}R^2\), measures the impact of individual features on the performance of a regression model by observing how the model’s \(R^2\) value changes when a feature is dropped. This technique is valuable because it can reveal the contribution of a specific feature to the overall explanatory power of the model, beyond a simple correlation. It is also a relatively straightforward to run.
However, there are some considerations to take into account when using the \({\Delta}R^2\) to evaluate key drivers, specifically relating to interactions and non-linearity between the features, similar to Pearson’s. The change in \(R^2\) doesn’t account for interactions between features unless specifically modeled. Therefore, if there is an interaction between 2 variables, that would have to be explicilty included in a linear regression model for it to have an impact on the \(R^2\) value. Also, non-linear relationships might not be captured effectively. If features are highly correlated, removing one might not show a significant change in \(R^2\) because its effect is being captured by the correlated features.
Methods Derived from Game Theory
Shapley Values
Shapley values are a concept derived from cooperative game theory used to fairly allocate the “payout” among players depending on their contribution to the total game. In the context of machine learning, Shapley values can be used to explain the contribution of each feature to the model’s prediction. Shapley values provide a detailed breakdown of how each feature contributes to the final prediction, which can often be more insightful than measures like the pearsons coefficients or \({\Delta}R^2\).
When computing Shapley values, the need to standardize data before computing Shapley values largely depends on the type of predictive model used. For linear regression models, standardizing might not be necessary for interpreting the contribution of features, as the model is fairly transparent and the contribution of features can be directly observed from the regression coefficients. However, if we are running and creating more complex models like neural networks or ensemble models (e.g., random forests, gradient boosting machines), standardizing features can help in comparing their contributions on a common scale, especially if the features vary widely in scale and units. Finally, regardless of the model, standardizing features can make the interpretation of Shapley values more straightforward across different features. When features are on the same scale, their Shapley values are easier to compare, as no single feature will dominate simply because of differences in scale.
Johnson’s Relative weights
Johnson’s relative weights analysis is a statistical technique used to determine the importance of predictor variables in a regression model, especially when dealing with multicollinearity among predictors. This method decomposes the total variance explained by the model into portions attributable to each predictor, taking into account the intercorrelations among them.
Johnson’s relative weights transform the raw regression coefficients by considering the correlation matrix of the predictors and results in a set of weights that reflect the contribution of each predictor to the model’s predictive power. Johnson’s weights provide a more nuanced view of feature importance than simple correlation or regression coefficients alone, particularly useful in models where predictors are not independent.
When computing Johnson’s relative weights, it is generally recommended to standardize the variables. Standardization ensures that each predictor contributes to the regression model on a comparable scale. This is crucial because Johnson’s Relative Weights are used to interpret the proportion of explained variance in the dependent variable that can be attributed to each independent variable. If the variables are not standardized, their weights might reflect their scale rather than their actual contribution to the model. Standardization removes this disparity, allowing a fair assessment of each variable’s relative importance based on their contribution to the model’s predictive power rather than their scale.
Methods Derived from Decision Trees and Ensemble Models
Decision Trees and Gini Importance
In Decision Trees and Ensemeble Models (such as Random Forest or Gradient boosting) methods such as Gini Importance and Permutation Importance are used to determine this varibale importance. Gini Importance - Measures how much each feature decreases the impurity in a decision tree, averaged over all trees in the ensemble. Permutation Importance - Measures the decrease in model performance (such as via accuracy or Root mean squared error) when the values of a feature are randomly shuffled, breaking the relationship between the feature and the target.
By understanding variable importance and conducting key drivers analysis, organizations can make data-driven decisions, prioritize resources, and develop strategies that target the most impactful factors.
When creating decision trees and computing the Gini Importance, standardizing the data beforehand is not necessary and generally doesn’t enhance the performance or interpretability of the model.
2. Data processing
import numpy as np import pandas as pd import pyrsm as rsm from sklearn.linear_model import LinearRegressionfrom scipy.stats import pearsonrimport statsmodels.api as smimport shapfrom sklearn.model_selection import train_test_splitfrom sklearn.ensemble import RandomForestClassifierimport seaborn as snsimport matplotlib.pyplot as plt from textwrap import wrapdriver_analysis = pd.read_csv('data/data_for_drivers_analysis.csv')driver_analysis.head(10)
brand
id
satisfaction
trust
build
differs
easy
appealing
rewarding
popular
service
impact
0
1
98
3
1
0
1
1
1
0
0
1
0
1
1
179
5
0
0
0
0
0
0
0
0
0
2
1
197
3
1
0
0
1
1
1
0
1
1
3
1
317
1
0
0
0
0
1
0
1
1
1
4
1
356
4
1
1
1
1
1
1
1
1
1
5
1
395
4
1
1
0
1
1
0
1
1
0
6
1
586
3
1
1
1
1
1
0
1
1
0
7
1
596
2
1
1
1
1
1
1
0
1
1
8
1
978
3
1
0
0
0
0
0
1
0
0
9
1
987
3
1
1
1
1
1
1
1
1
1
We are now going to see these methods in action. We are using a database that has 2553 observations across 9 variables, with the response variable being the satisfaction score. The following regressors are all binary variables:
trust - Is offered by a brand I trust
build - Helps build credit quickly
differs - Is different from other cards
easy - Is easy to use
appealing - Has appealing benefits or rewards
rewarding - Rewards me for responsible usage
popular- Is used by a lot of people
service - Provides outstanding customer service
impact - Makes a difference in my life
Respondents were asked to respond yes or no to 9 questions related to attributes of a payment card. They then provided an overall satisfaction score from 1-5. We will use the methods above to determine which attributes contribute the highest to respondents overall satisfaction of the payment cards.
Before we demonstrate differences in the relative importance values, we need to first assess the multicollinearity between the variables. Due to the Halo Effect, we see that respondents tend to rate something higher on all attributes if they like a brand, but also rate something lower on all attributes if they dislike a brand. Therefore, we often see that in perception datasets, there is a high level of multicollinearity. Below, we will run a correlation matrix to see which variables are highly correlated with each other.
# Standardizing the Driver Analysis Dataframeda_standardized = driver_analysis.copy().iloc[:, 2:12]da_standardized = (da_standardized - da_standardized.mean()) / da_standardized.std()da_standardized.head()#breaking out our Predictor and Dependent variablesX_standardized = da_standardized[["trust", "build", "differs", "easy", "appealing", "rewarding", "popular", "service", "impact"]]y_standardized = da_standardized['satisfaction']#Fit a linear regression modelmodel = LinearRegression()model.fit(X_standardized,y_standardized)#extract out coefficients and intercept from our linear regression modelcoefficients = model.coef_intercept = model.intercept_
#Creating an empty dictionary to store our coefficients in pearson_corr_matrix = {}#extracting one coefficient at a time to calculate the correlation value offor column in da_standardized.columns:if column !='satisfaction': corr, _ = pearsonr(da_standardized[column], da_standardized['satisfaction']) pearson_corr_matrix[column] = corrtotal_sum =sum(pearson_corr_matrix.values())percentage_data = {}# Calculate and print the percentage of the sum for each valuefor key, value in pearson_corr_matrix.items(): percentage = (value / total_sum) *100 percentage_data[key] = percentage# Convert the new dictionary to a DataFramepearson_corr_df = pd.DataFrame(list(percentage_data.items()), columns=['Features', 'Pearson_corr_%'])pearson_corr_df["Pearson_corr_%"] = pearson_corr_df["Pearson_corr_%"].round(1)print(pearson_corr_df)
Features Pearson_corr_%
0 trust 13.3
1 build 10.0
2 differs 9.6
3 easy 11.1
4 appealing 10.8
5 rewarding 10.1
6 popular 8.9
7 service 13.0
8 impact 13.2
# Sum up the absolute values of Shapley values for each featurefeature_importance = np.sum(shap_values.values, axis=0)# Calculate the total sum of all Shapley valuestotal_importance = np.sum(np.abs(feature_importance))# Compute the percentage contribution of each featurepercentage_contributions =100* feature_importance / total_importancepercental_total = percentage_contributions.sum()print(percental_total)# Create a DataFrame to display the resultsshapley_df = pd.DataFrame({'Feature': X_standardized.columns,'feature_importance': feature_importance,'Shapley Value Sum': total_importance,'Shapley_percent_Total': percentage_contributions})shapley_df["Shapley_percent_Total"] = shapley_df["Shapley_percent_Total"].round(1)print(shapley_df)shapley_df_short = shapley_df[["Feature", "Shapley_percent_Total"]]
Mean Decrease in the Gini Coefficient from a Random Forest
X_train, X_test, y_train, y_test = train_test_split(X_unstandardized, y_unstandardized, test_size=0.2, random_state=42)rf = RandomForestClassifier(n_estimators=1000, random_state=42, criterion='gini')# Train the modelrf.fit(X_train, y_train)# Extract feature importances (Mean Decrease in Gini)feature_importances = rf.feature_importances_# Create a DataFrame to hold the feature importancesfeatures = X_unstandardized.columnsimportance_df = pd.DataFrame({'Feature': features,'Importance': feature_importances})# Sort the DataFrame by importanceimportance_df = importance_df.sort_values(by='Importance', ascending=False)importance_df["Importance_percentage"] = (importance_df["Importance"] / importance_df["Importance"].sum()) *100importance_df["gini_percent"] = importance_df["Importance_percentage"].round(2)gini_index = importance_df[["Feature", "gini_percent"]]
3. Key Driver Analysis and Interpretation
#Merging all of the dataframes together#Merging Pearsons with Standardized Linear Coefficientmerged_df = pd.merge(pearson_corr_df, SLC_df, left_on ='Features', right_on ='Predictor', how ='left')#Merging on Shapley Percentsmerged_df = pd.merge(merged_df,shapley_df_short, left_on ='Features', right_on ='Feature', how ='left')#Merging on Usefulness Percentagesmerged_df = pd.merge(merged_df,usefulness_df, left_on ='Features', right_on ='feature', how ='left')#Merging on Johnsons Percentagesmerged_df = pd.merge(merged_df,johnsons_df, left_on ='Features', right_on ='Feature', how ='left')#Merging on Gini Index %merged_df = pd.merge(merged_df,gini_index, left_on ='Features', right_on ='Feature', how ='left')#dropping redundant columns and setting the new indexmerged_df.drop(columns=["Predictor", "Feature_x", "feature", "Feature_y", "Feature"], inplace=True)merged_df.set_index('Features', inplace=True)
import seaborn as snsimport matplotlib.pyplot as plt from textwrap import wrap
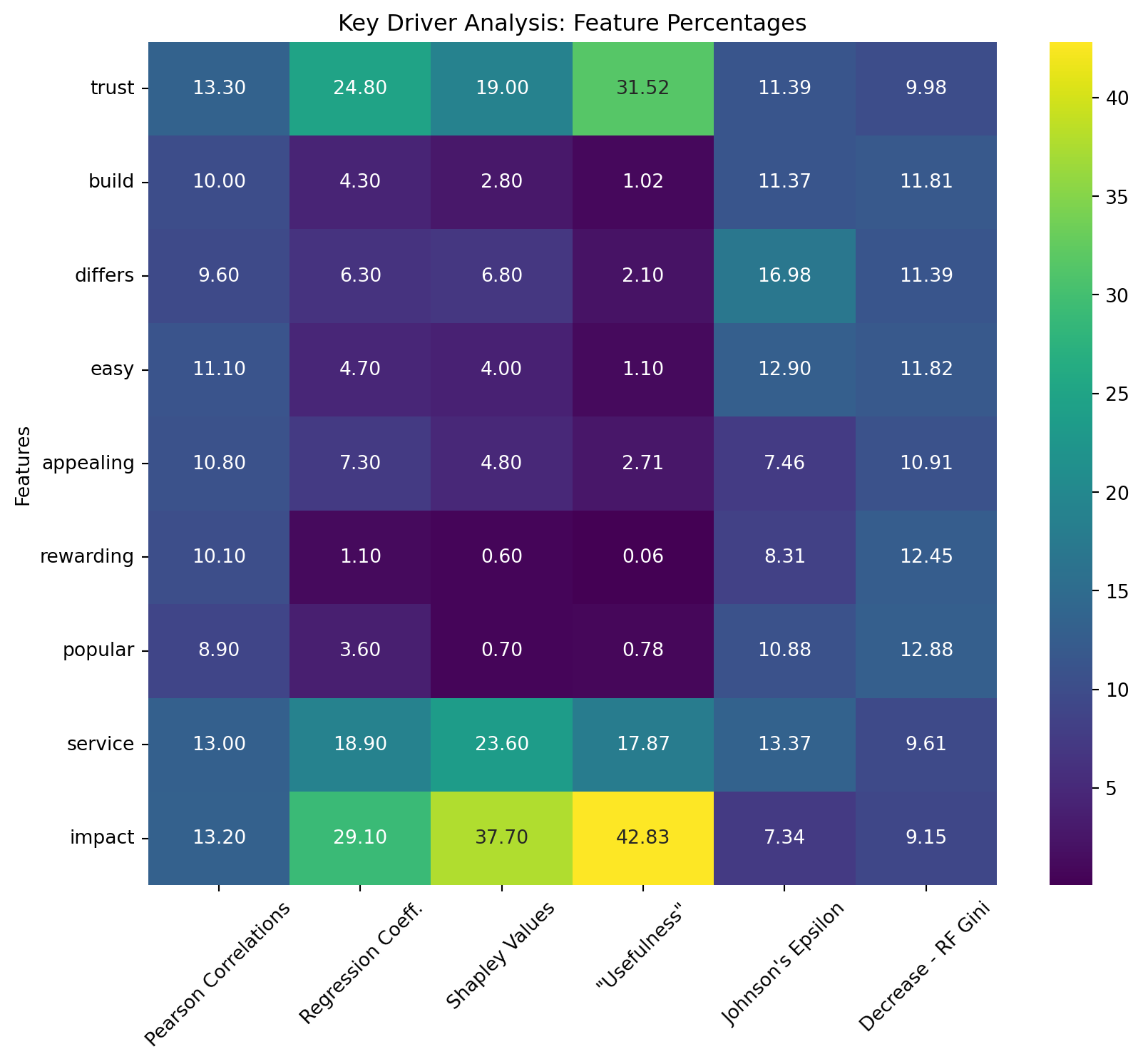
Above is the table recreation showing the importance scores for various features across different driver analysis methods, each normalized as percentages. These methods help us understand which features most significantly affect the predictive power of a model. We can review each column and identify the most important features as determined by each respective method.
Pearson Correlations: This column reflects the linear correlation between each feature and our target variable, satisfaction. Higher values indicate a stronger linear relationship. Features like trust, service, and impact show relatively high correlation, suggesting these are important in a linear sense.
Regression Coefficients: These scores are derived from a regression model, showing how much the target variable changes with a one-unit change in the feature, all else being equal. Impact, trust, and service, have higher coefficients, indicating significant influence on the model output.
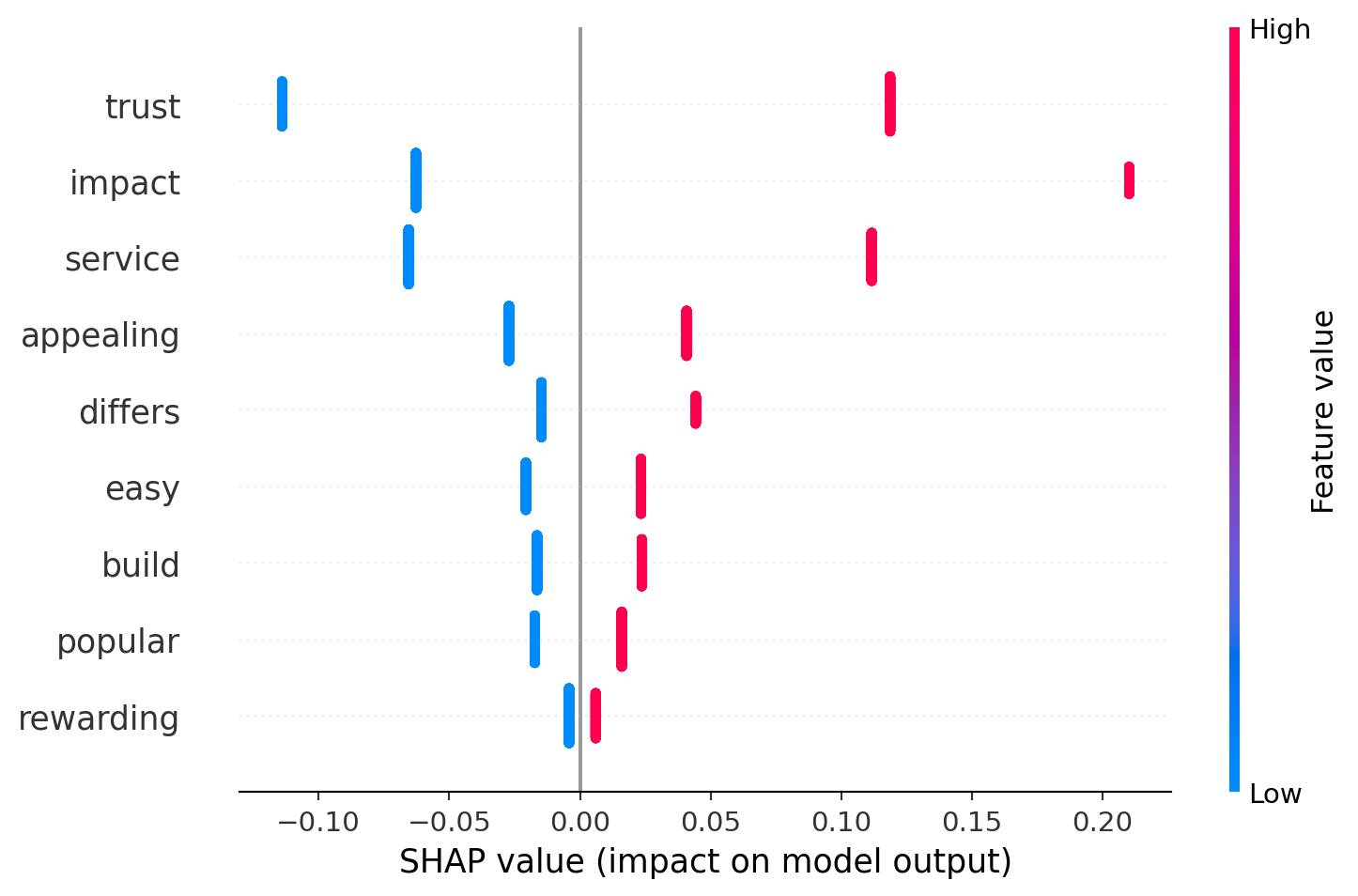
Shapley Values: This method distributes the prediction value among the features, attributing the impact of each feature on the outcome of the model. Again, Impact, trust, and service score high, underscoring their importance in contributing to model predictions.
“Usefulness”: This value identifies impactful features via their respective change in the \(R^2\) value. Impact and trust show exceptionally high values, highlighting their critical role.
Johnson’s Epsilon: This metric likely measures the change in predictability when a feature is altered. “Differs”, “easy”, and “service” show higher values, suggesting these features significantly impact model predictability.
Decrease - RF Gini: Derived from Random Forests, this shows the decrease in node impurity (Gini index) brought by each feature. “Popular”, “rewarding”, and “easy” have higher values, indicating their utility in improving model decisions through increased purity in node splits.
Based on the heatmap and table created above, we see that there are three overall high impact features. Impact, trust, and service consistently show high importance across multiple metrics, suggesting they are crucial for accurate predictions. Features like easy, differs, and appealing exhibit moderate importance scores across various methods, indicating they play a secondary yet meaningful role in model predictions.Rewarding and popular, despite their roles, seem to have less influence compared to other features, particularly in metrics outside the Decrease - RF Gini. In this assignment, we were trying to recreate the table in slide 19. Despite not getting the exact same numbers, I did get the same ordering of important features.